








Centric Market Intelligence
Gain a 360° view of the entire market
Provide your teams with invaluable data for product trends, pricing intelligence and competitor monitoring.
Analyze competitive assortments and prices.
Grasp market trends and consumer preferences.
Drive product decisions and maximize revenues.
Powering the world’s top fashion, footwear, home and beauty companies with unrivalled data quality.













And the data powering leading fashion trend reports from global consulting firms and industry media.
McKinsey & Company: The State of Fashion 2023Data-driven decision-making based on real-time market intelligence
Manually collecting competitive data is time-consuming, never fully accurate, constantly out of date and full of errors. Quickly gain a 360° view of the entire market and start predicting your competitor’s next move!
What products are your competitors selling?
What are your competitors doing, selling and promoting? Know the makeup of their assortment mix and the overlapping SKUs with your own product assortment.
What are the up-and-coming trends?
Find out what consumers are looking for through competitive sell-through and market search data. Discover which trends are peaking and those with staying power.
Are your inventory investments right?
Which products, categories, sizes, styles and colors are competitors investing their inventory in? Ensure your own assortment reflect what’s happening in the wider market.
When are competitors discounting items?
Don’t be late to discount items! Pre-empt your competitors’ promotional activities and better align your own discounting strategy to drive sales and improve profit margin.
What are the pricing strategies in the market?
Price too high and you may lose customers, price too low and you’ll lose profit margin and brand value. Benchmark yourself against competitors to quickly discover pricing opportunities.
Are you increasing prices due to inflation?
Gain visibility into exactly how competitors are pricing. Discover when to expand products to higher and lower price points to match competitors and capture the market.
Attribution-Rich Taxonomy
Enriched data that is incredibly flexible to manipulate and analyze
Quality is at the forefront of our data processing pipeline. From collection and normalization to enrichment and analysis, we’ve trained our machines to see the world the way you do.
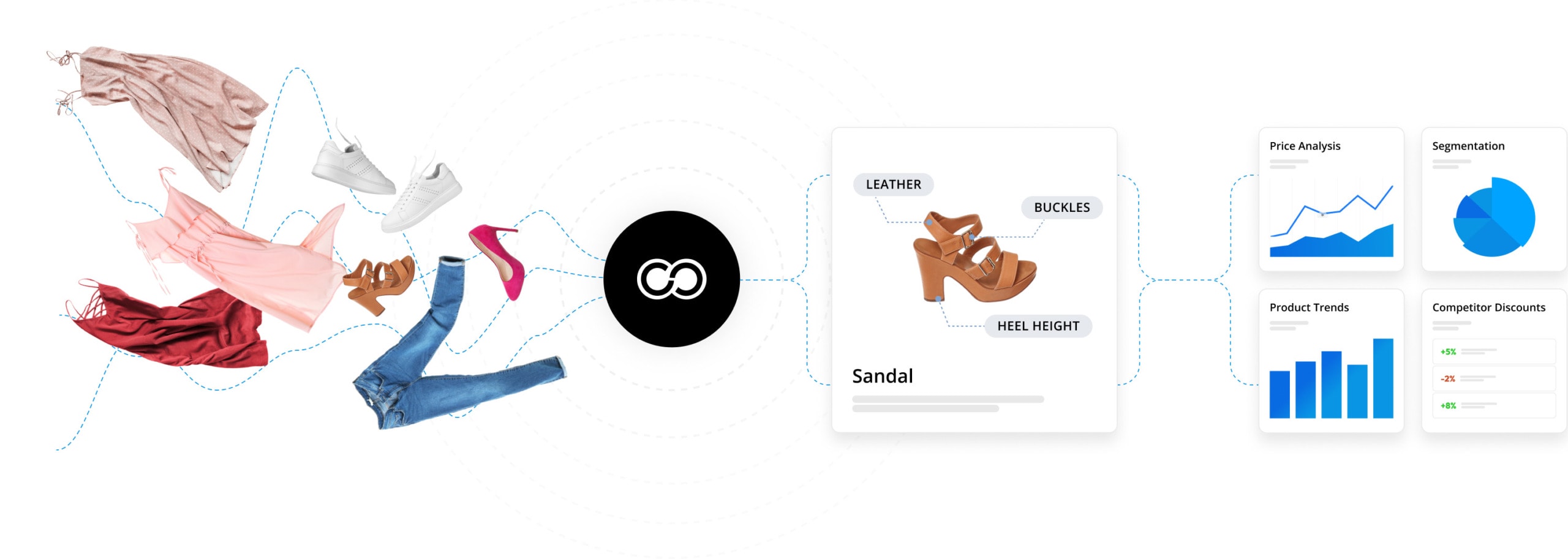
Extract all competitor data
Build an accurate and complete snapshot of the retail landscape by collecting all products and all information around those products from competitors’ eCommerce sites.
Correctly categorize products
Standardize products using computer vision and natural language processing to accurately compare like-for-like products. Eliminate double counting to ensure accurate analysis.
Build trust with transparency
Data you can trust to make decisions with. Each and every eCommerce product can be traced back and verified, right to the source. Our data is unrivalled in quality.
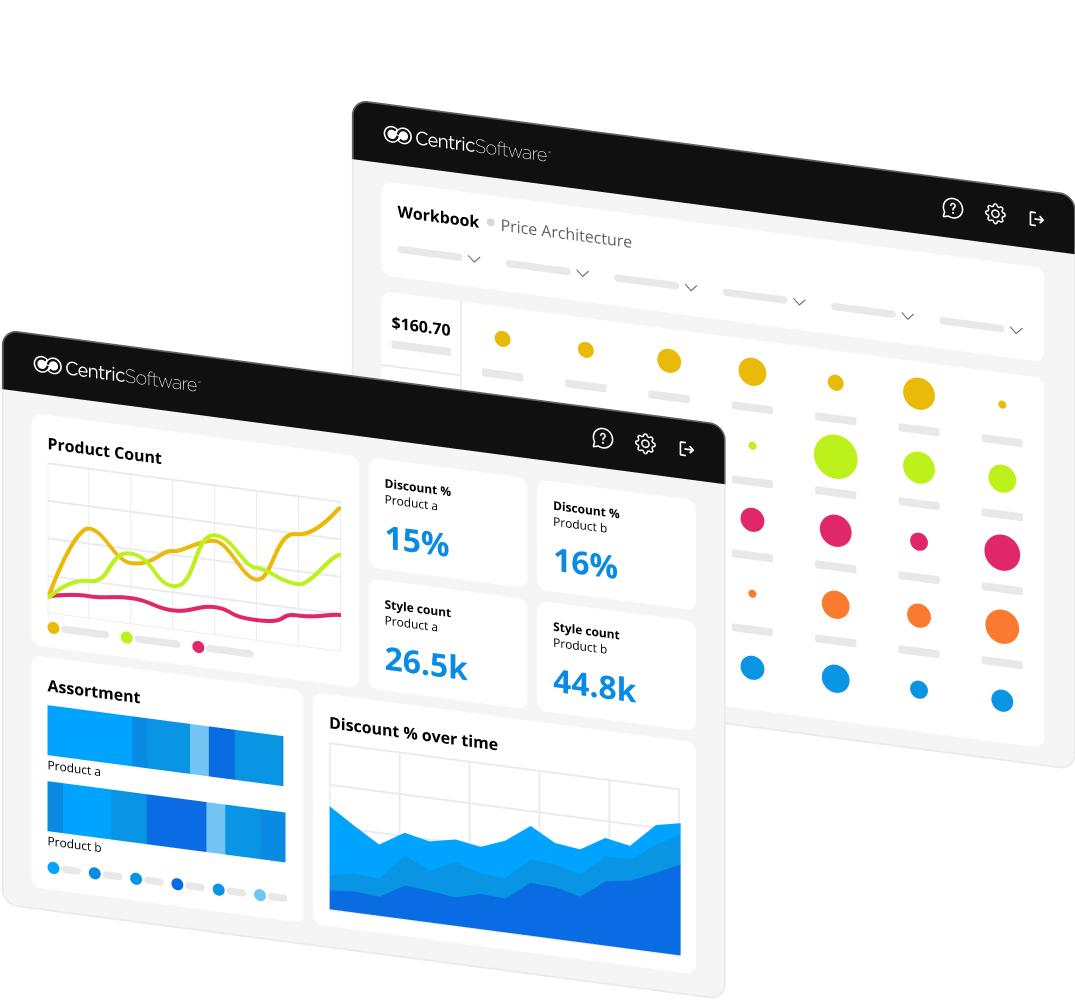
Visualize Data Like Never Before
Easily build a range of charts and graphs to see competitive data visually. Quickly compare and benchmark yourself against competitors from price point to assortment categories.

Extract all competitor data
Build an accurate and complete snapshot of the retail landscape by collecting all products and all information around those products from competitors’ eCommerce sites.

Correctly categorize products
Standardize products using computer vision and natural language processing to accurately compare like-for-like products. Eliminate double counting to ensure accurate analysis.
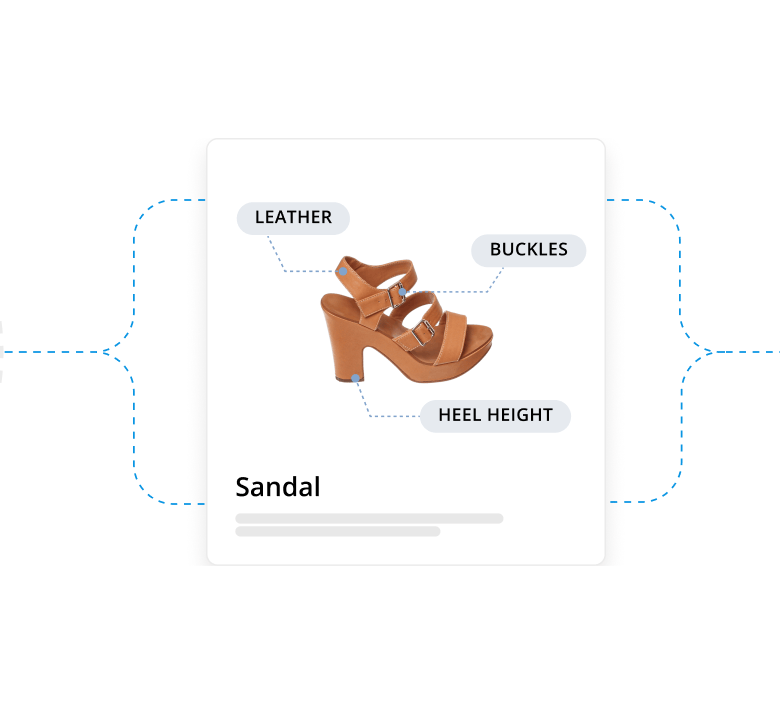
Build trust with transparency
Data you can trust to make decisions with. Each and every eCommerce product can be traced back and verified, right to the source. Our data is unrivalled in quality.
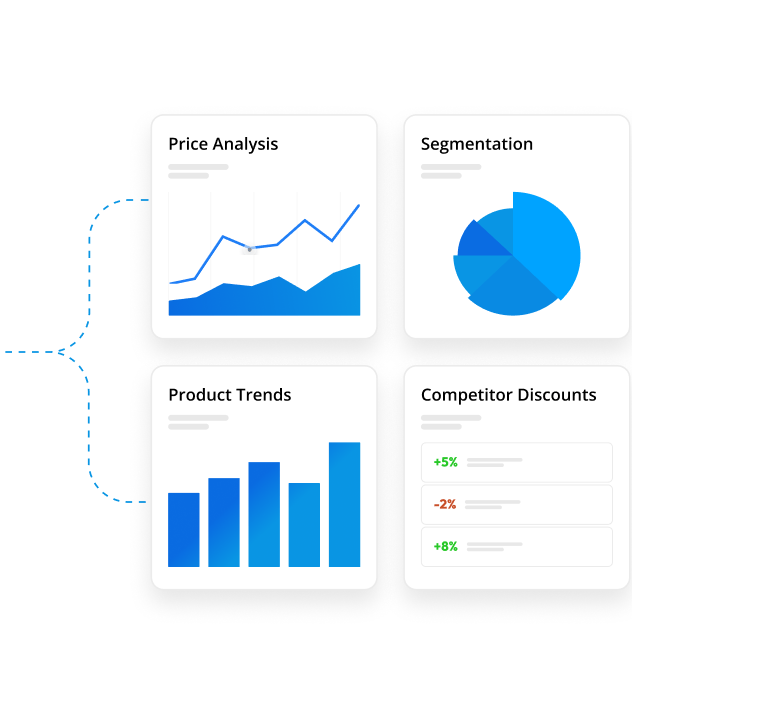
Visualize Data Like Never Before
Easily build a range of charts and graphs to see competitive data visually. Quickly compare and benchmark yourself against competitors from price point to assortment categories.
Slice and dice the data in 14,000 unique ways.
Drill down, investigate and probe the data in 1000s of unique combinations, viewpoints and angles, whether looking at historical or real-time data.
See it in action:
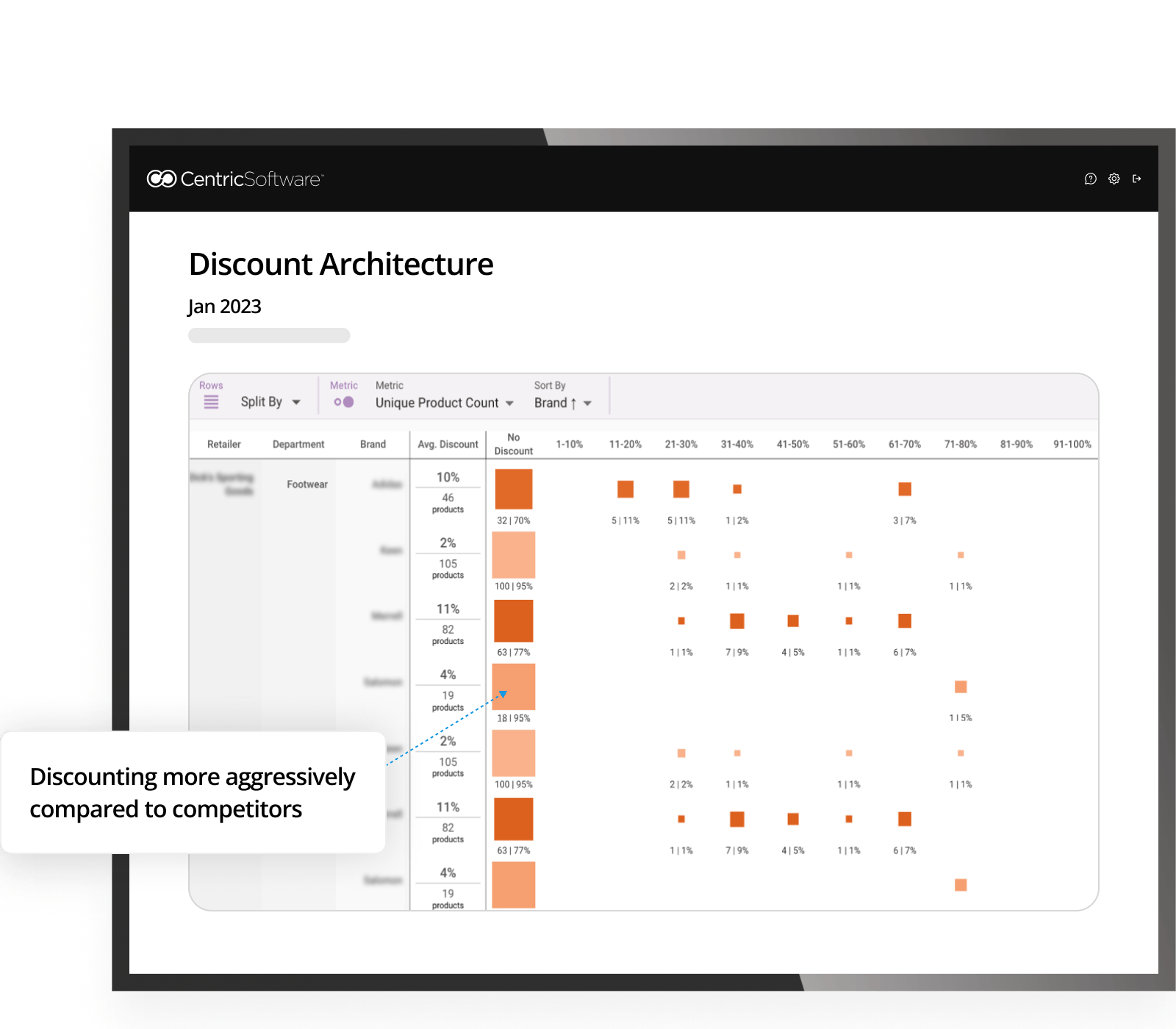
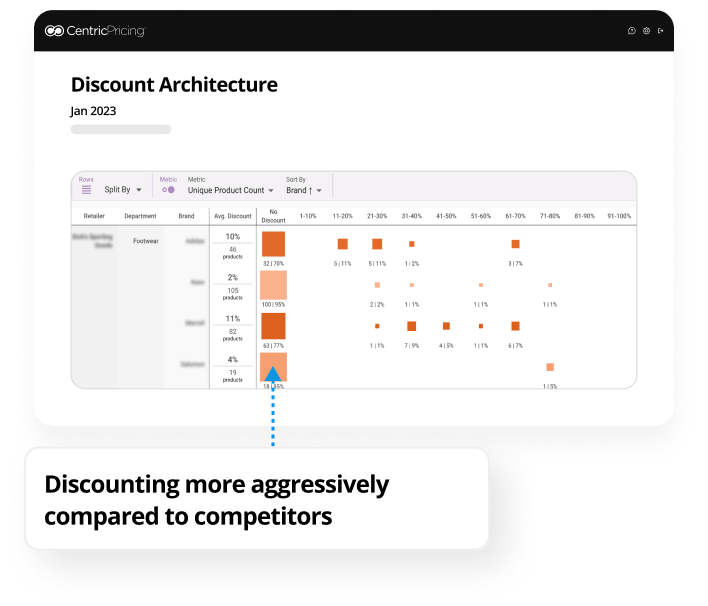
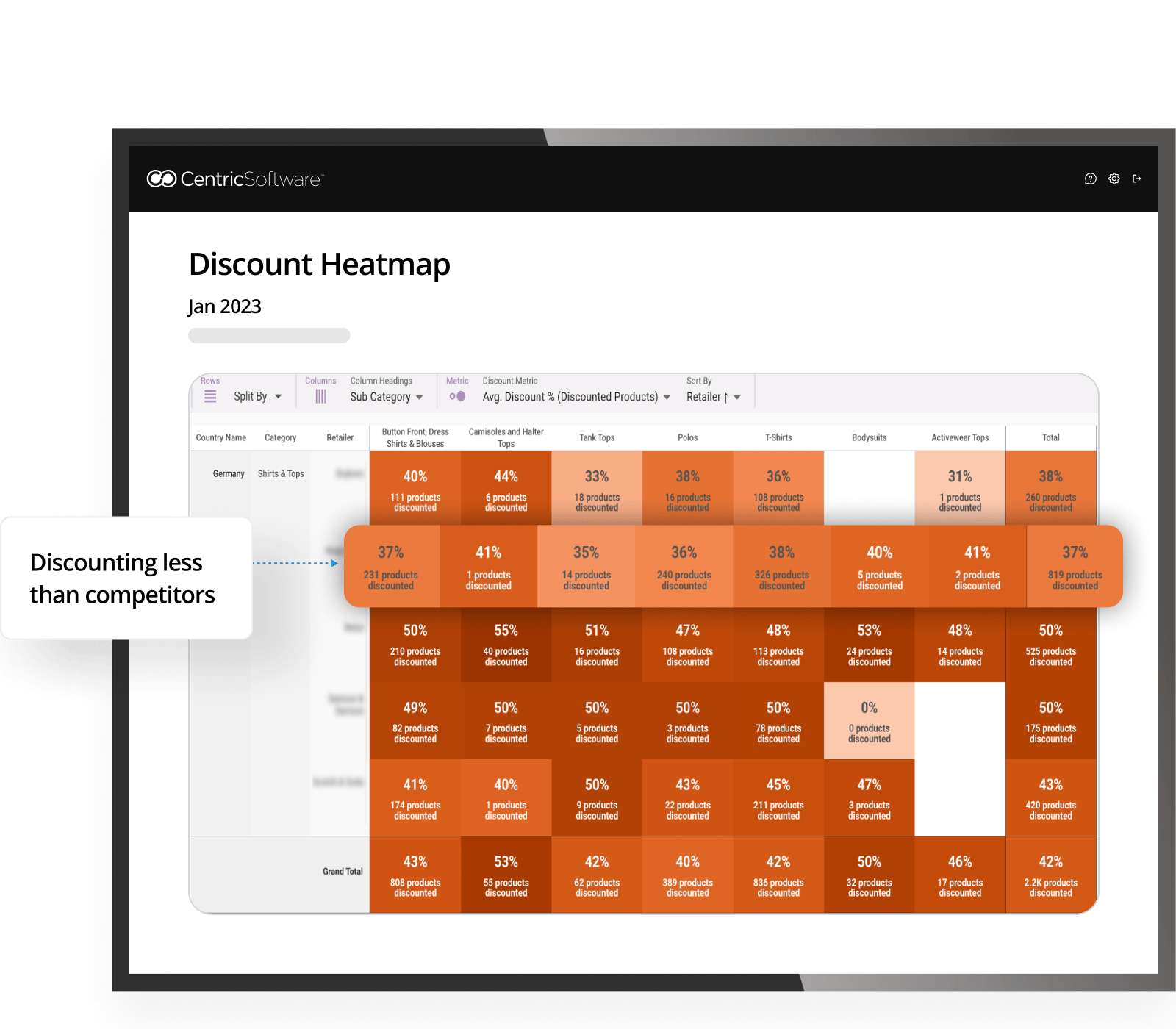
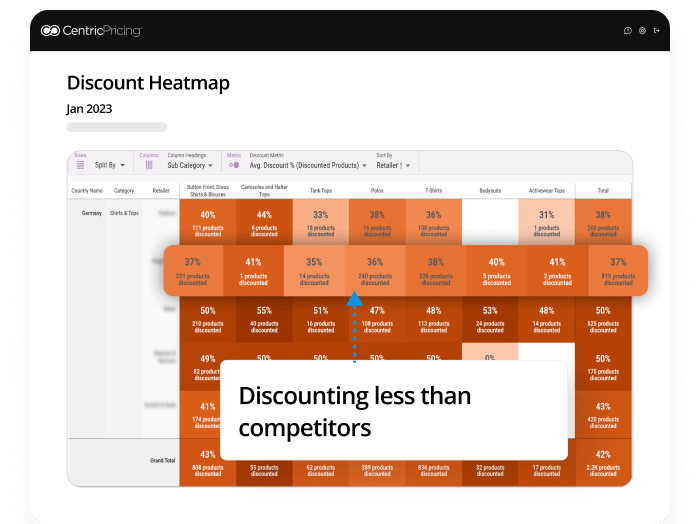
Uncover if your company is discounting more aggressively than competitors. This indicates the potential to scale back discounting slightly to claw back some margin but still stay competitive.
Here, compared to competitors, this company discounts a lower % of their assortment. If a company has a high amount of sale items all concentrated into one category, this indicates an opportunity to discount more parts of their assortment and offer a variety to customers.
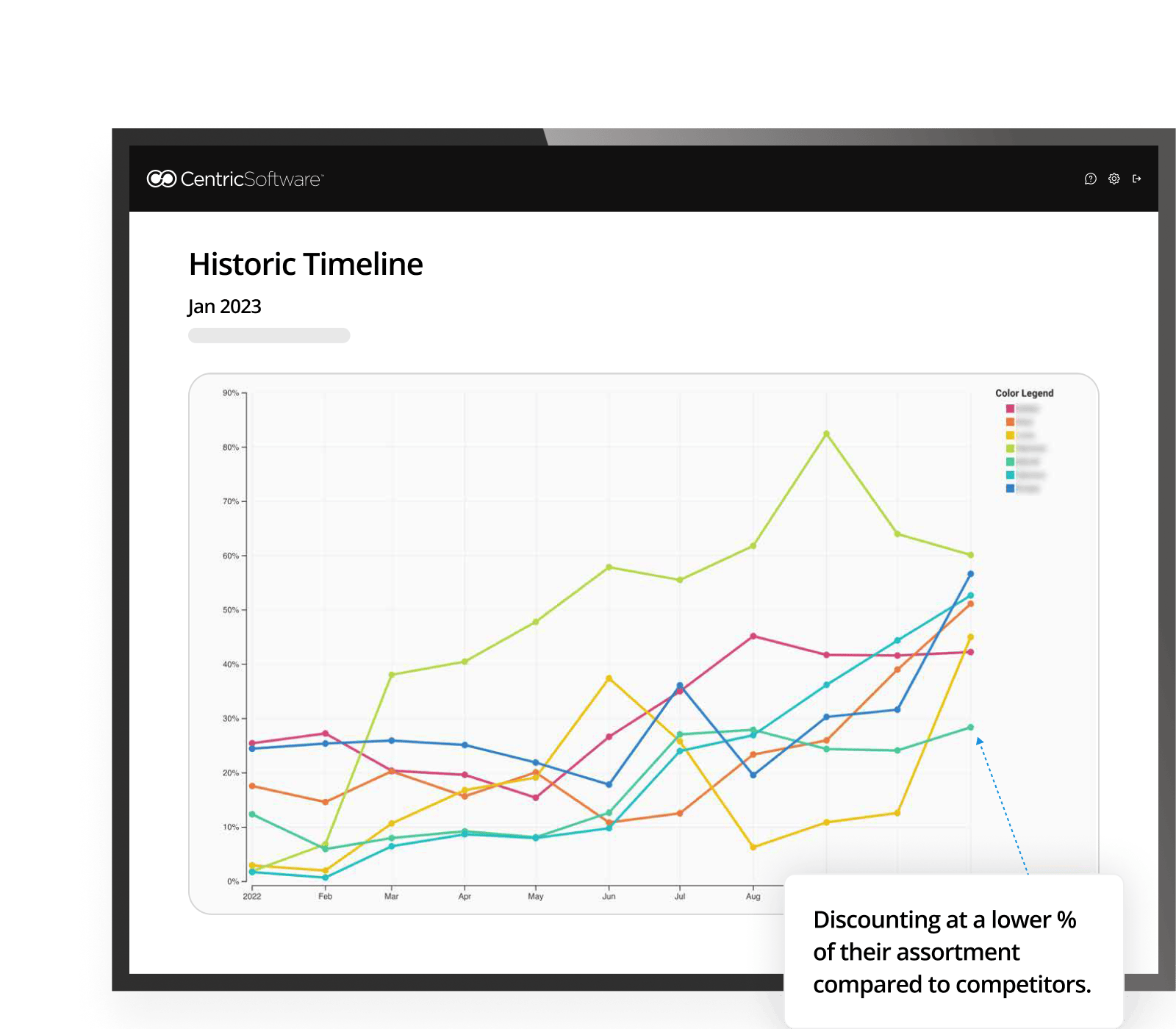
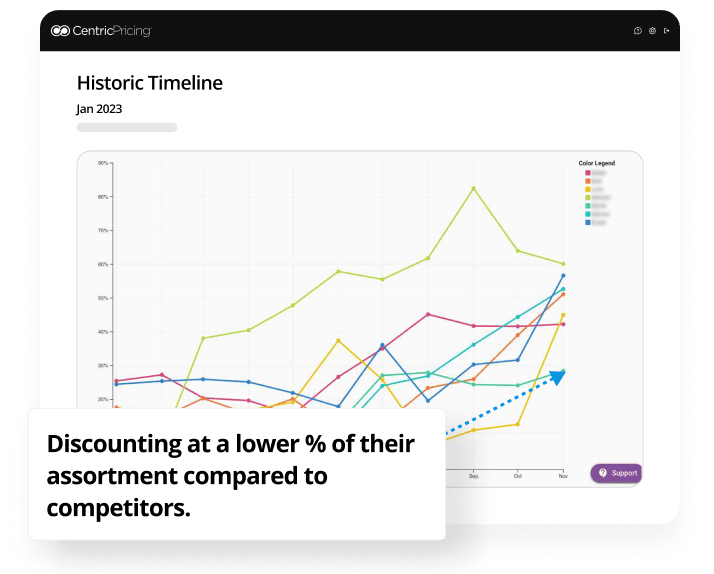
From the graph, brands and retailers can discover their discounting strategy in comparison to the wider market. Is it too aggressive or not enticing enough? This brand could discount more aggressively to drive sales of slow-moving products.
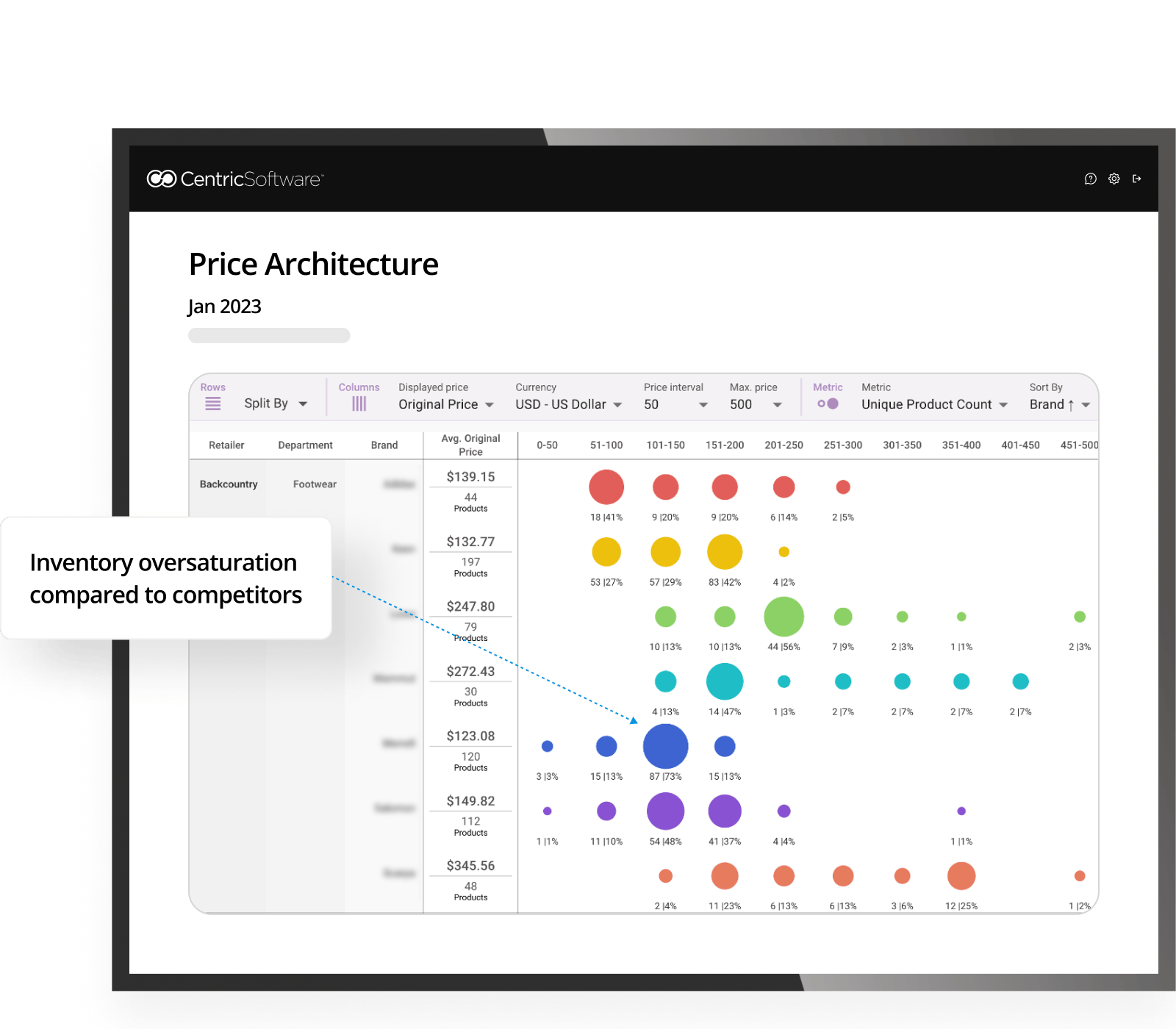
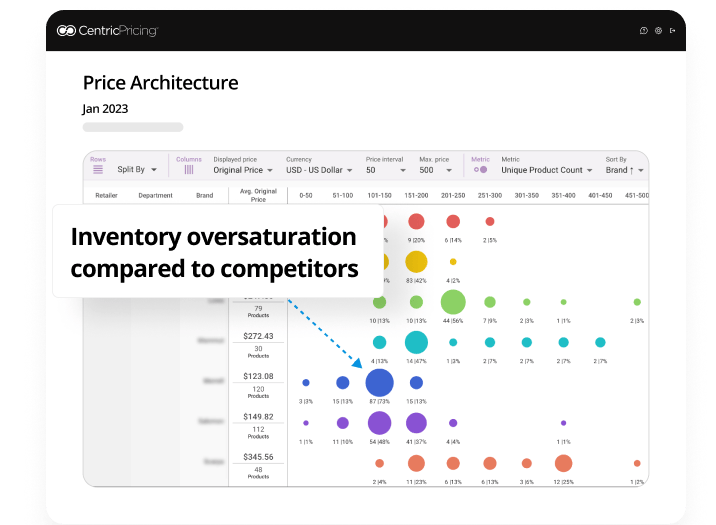
From this image, it looks like this brand is concentrating a lot of inventory in a particular price point, much more so than competitors. This shows there is room to expand into higher price points and drive margin but still stay competitive to similar brands.
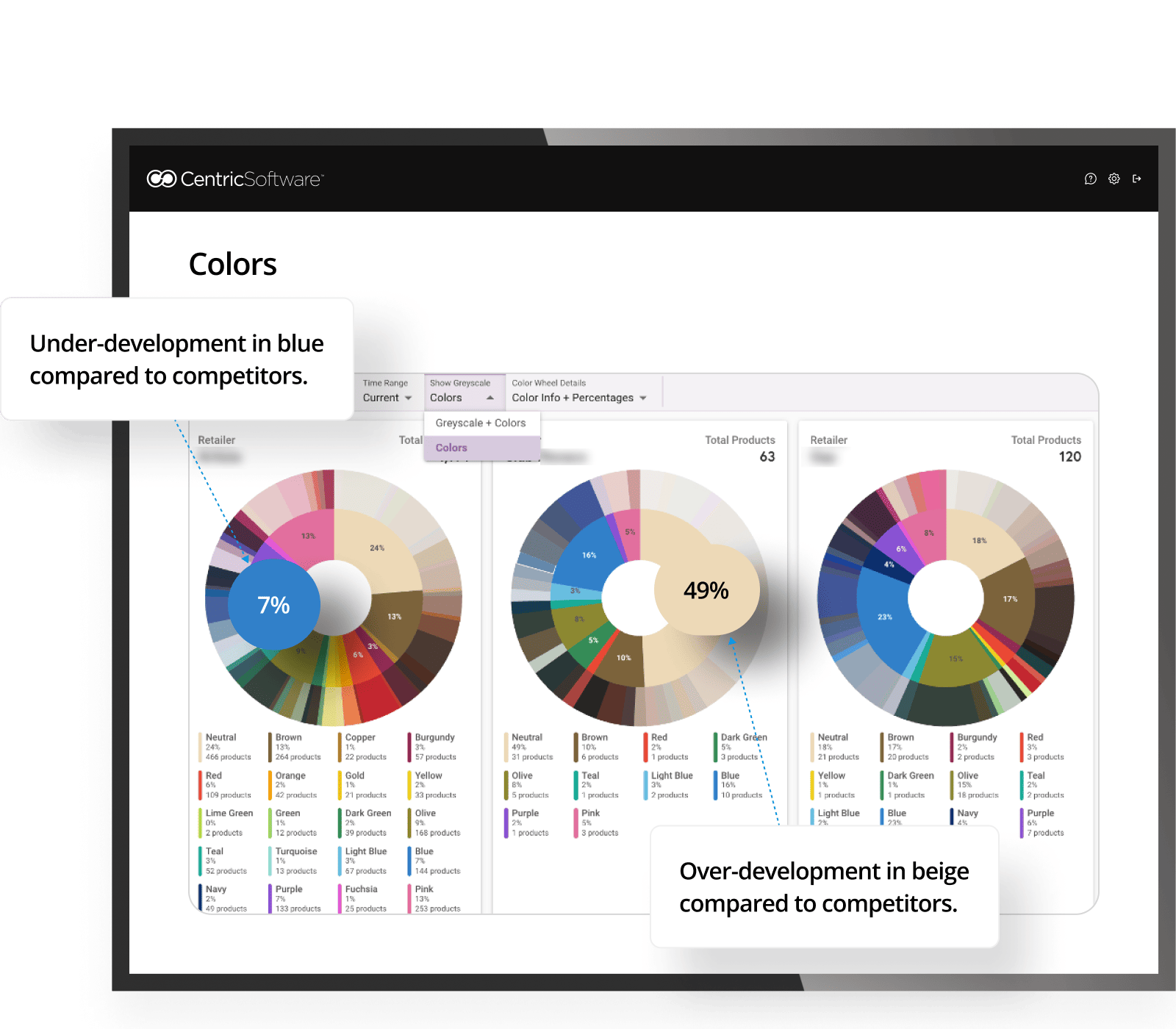
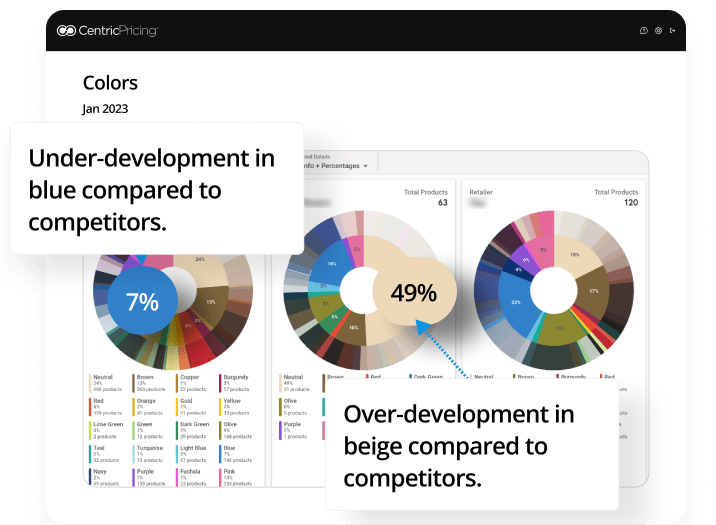
Slice and dice competitor data by color and gain a quick snapshot of the color make up of competitors. This image indicates there may be an under-development in blue but a competitor looks like they’re over-developing in beige.
17,500+ Brands Trust Centric Software









“We were aiming for #1 and we felt that Centric was the market leader by a long shot in comparison to the others.”

“Centric Market Intelligence is like having an invisible member on your team to back you up on every decision that you make.”
Uncover powerful insights with the
Market Intelligence platform
Ecommerce Analytics
Intelligence
Trends & Promotions
Quickly analyze and benchmark competitors
Truly understand the competitor dynamics in your market through historical and real-time data. Quickly and easily benchmark competitors to optimize your overall product offering.
 Execute quick analysis to discover competitors’ pricing and discounting strategies, and their assortment and inventory set.
Execute quick analysis to discover competitors’ pricing and discounting strategies, and their assortment and inventory set.
Discover the fast-moving and best-sellers within the industry and your own white space opportunities to drive sales and maximize margins.
Take the guesswork out of pricing and discounting whether planning and strategizing pre-season, or trying to move inventory in-season.
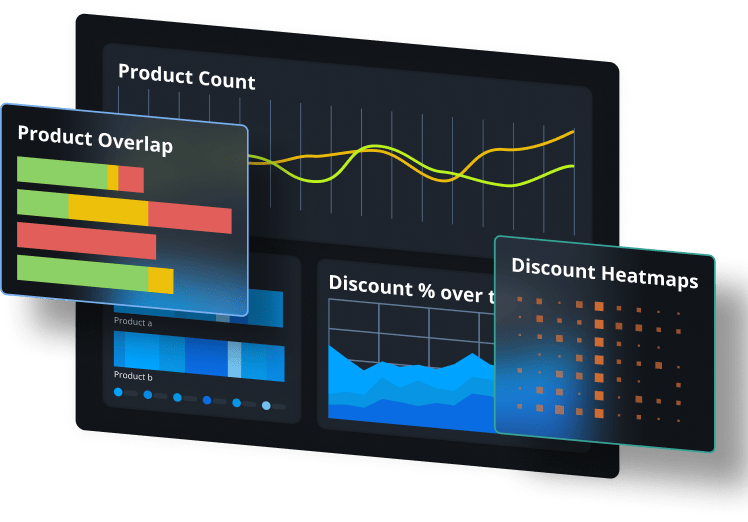
Understand the market with in-depth reports
Keep up to date with the industry with data that is contextualized in a range of curated reports, including insights across categories, colors, products and geographies.
Fully understand all aspects of the retail industry and uncover products with the highest-sell out rate or those that are being heavily discounted.
Utilize this visual and summarized data across teams, and facilitate merchandisers and buyers to drive strategy and planning discussions.
Enable teams bringing new products to market to fully grasp the competitor landscape pre-launch.

Stay on top of new and emerging trends
Identify up-and-coming trends and what your consumers are searching for. Explore search data so teams can isolate trends and learn more about specific categories or particular search terms.
Discover how many people are searching for categories and at what percentage increase. See which trends are growing steadily and which are short-lived.
Ensure merchandising teams are including stable trends in future assortments. Debut collections to test response and de-risk any new inventory decisions.
Gain access to a visual archive of what competitors’ homepage and newsletters look like and pre-empt your competitors’ promotional calendar.

Reliable Data you can trust
Build strong data foundations to accurately
benchmark against competitors

Data crawled every single day
Our data is updated every 12-24 hours.

2 million products a week
The system collects over 2 million products every single week.

High-quality data transparency
Each and every product is verifiable back to the source.

50 million data points
Processes 50 million enhancements around those collected products.
Centric Market Intelligence delivers invaluable data for product trends and competitor monitoring. Learn more in just 60 minutes.
Request a demoMore Centric Market Intelligence resources












A flexible and scalable digital foundation for growth
Explore Centric’s AI market-driven solutions
Optimize each step of bringing a product to market, whether at the pre-season, in-season or end-of-season cycle. Streamline processes, reduce costs, maximize profitability and drive sustainability.
Centric PLM
Reduce costs and time to market. Improve collaboration to get products to market fast while improving sustainability with market-leading product lifecycle management.
Learn moreCentric Planning
Build and execute your Merchandise Financial Plan and develop assortments to boost margins, improve forecasting and optimize results with powerful, AI-driven retail planning.
Learn moreCentric Pricing & Inventory
Automate pricing decisions for all products across categories and channels and optimize allocation and replenishment to increase margins, revenue and sell-through.
Learn moreCentric Market Intelligence
Gain insights into competitor assortment and pricing strategies, understand consumer trends and buying behavior and spot market opportunities.
Learn moreCentric Visual Boards
A visual-first approach to bridge gaps between teams and systems. Accelerate and transform decision making with a visual pivot table.
Learn more